
流程发现算法第2讲|Alpha系列算法
发布时间:2022-08-29
回顾上一讲Alpha算法的内容,我们发现Alpha算法存在很多无法处理的一些问题(如短循环、重名任务、不可见变迁等)。为此,研究学者提出了一系列Alpha算法的扩展算法进行完善,常用的有Alpha+算法、Tsinghua-Alpha算法、Alpha++算法、Alpha$算法、Alpha#算法和Alpha*算法,下面我们对Alpha系列算法进行简单介绍。
1 Alpha+算法
如图,N1为长度为1的短循环Petri网,应用基础Alpha算法挖掘时,通常会导致右上角的错误结果,这是由于在基础Alpha算法中不存在B>B这种结构;N2为长度为2的短循环Petri网,应用基础的Alpha算法挖掘时,通常会导致右下角的错误结果,这是由于ABA序列常常被识别为A||B和B||A,而不是A->B,B->A。
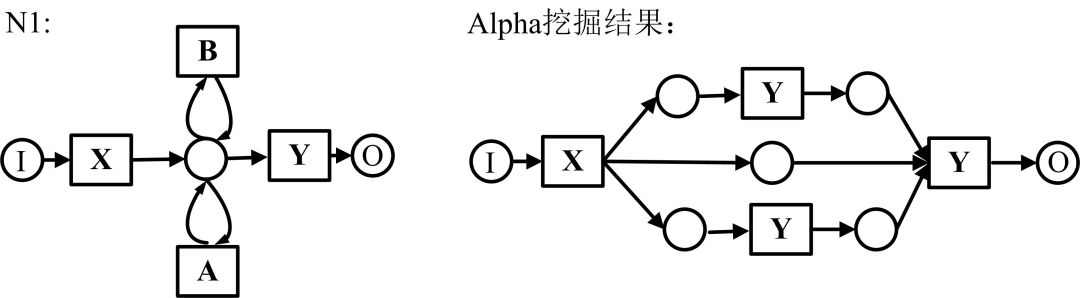

Alpha算法不能识别上述两种类别的Petri网,Alpha+算法进行了如下改进:
(1)定义“XYX”次序关系,区分短循环和并行;

(2)将流程挖掘分为三阶段过程:预处理,处理,后处理。在预处理步骤中移除长度为1的短循环任务,在后处理步骤中将短循环任务添加到模型的正确位置.
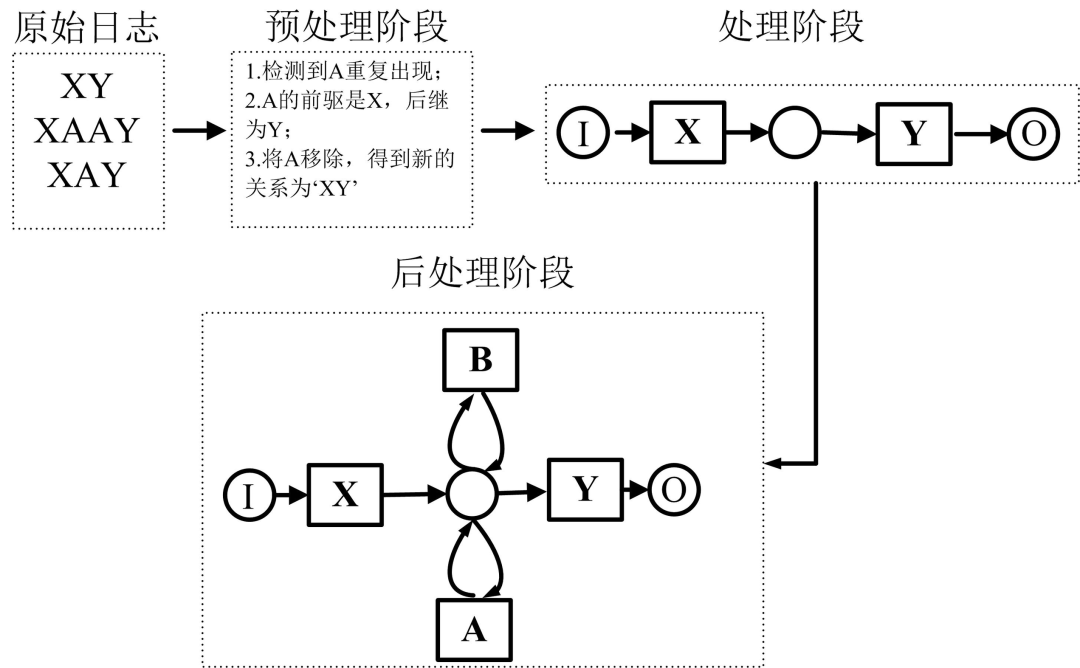
2 Tsinghua-Alpha算法
一个变迁的执行对应两个事件类型(strat和complete),换言之,事件的执行需要时间,是带有生命周期的。Alpha算法并不能区分这种事件到底是串行短循环还是并行短循环。为此,Tsinghua-Alpha算法从该角度出发,定义了如下关系,用于处理带有生命周期的事件日志。
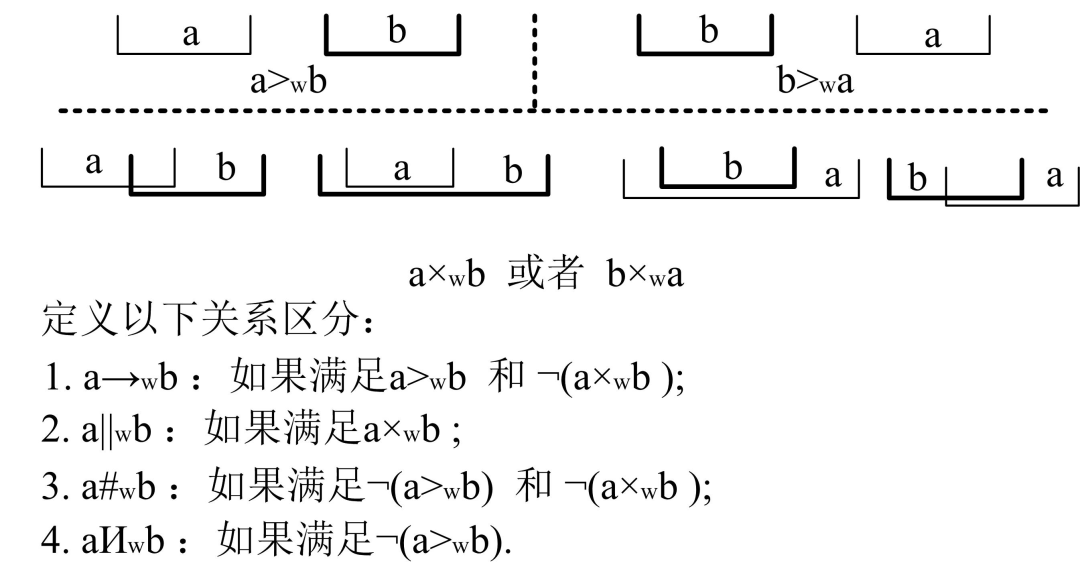
3 Alpha#算法
基础Alpha算法无法处理不可见任务,对应Petri网也就是不可见变迁或者静默变迁。含有不可见变迁的Petri网模型具体分为SIDE类型、SKIP类型、REDO类型、高级SKIP类型、高级REDO类型以及SWITCH类型,各类型用例如下所示:
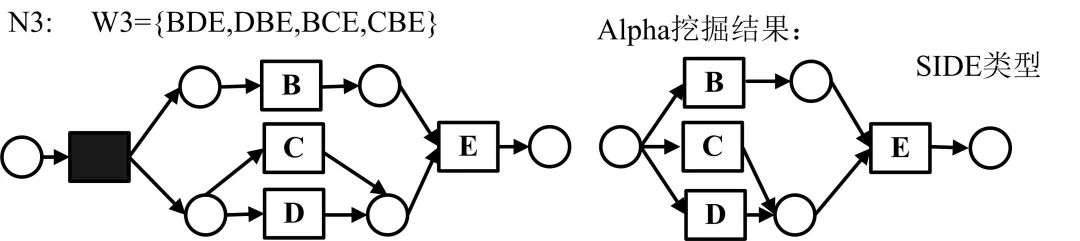
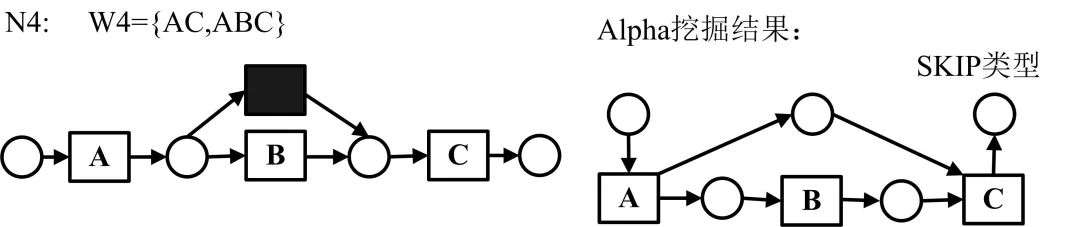

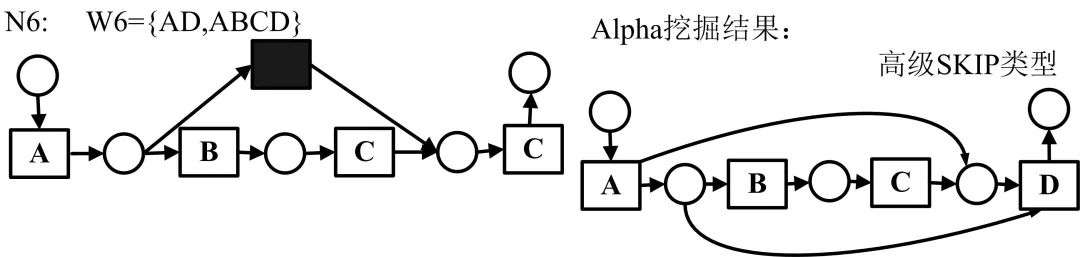
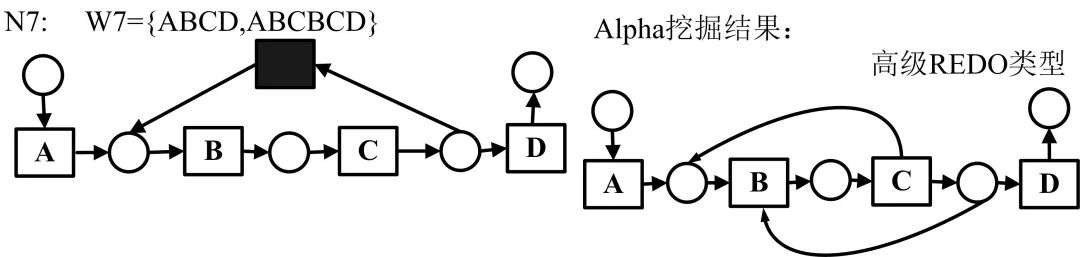
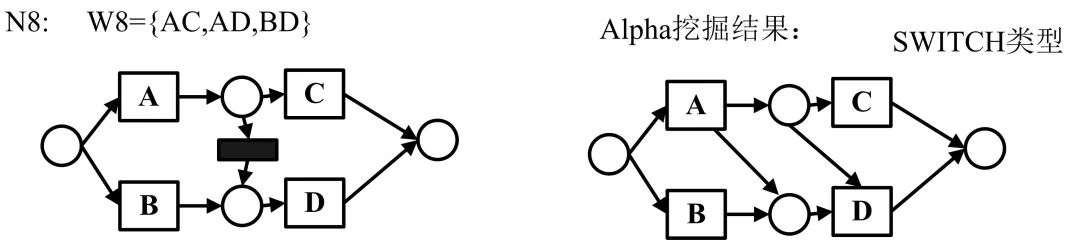
对于上述类型结构,Alpha#算法定义了一种虚假的依赖关系,如下所示:
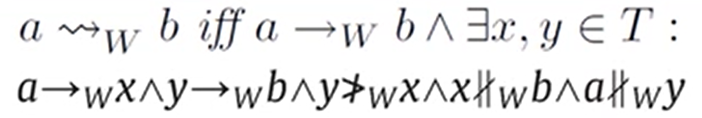
若满足上述关系,则对应的Petri网结构为:
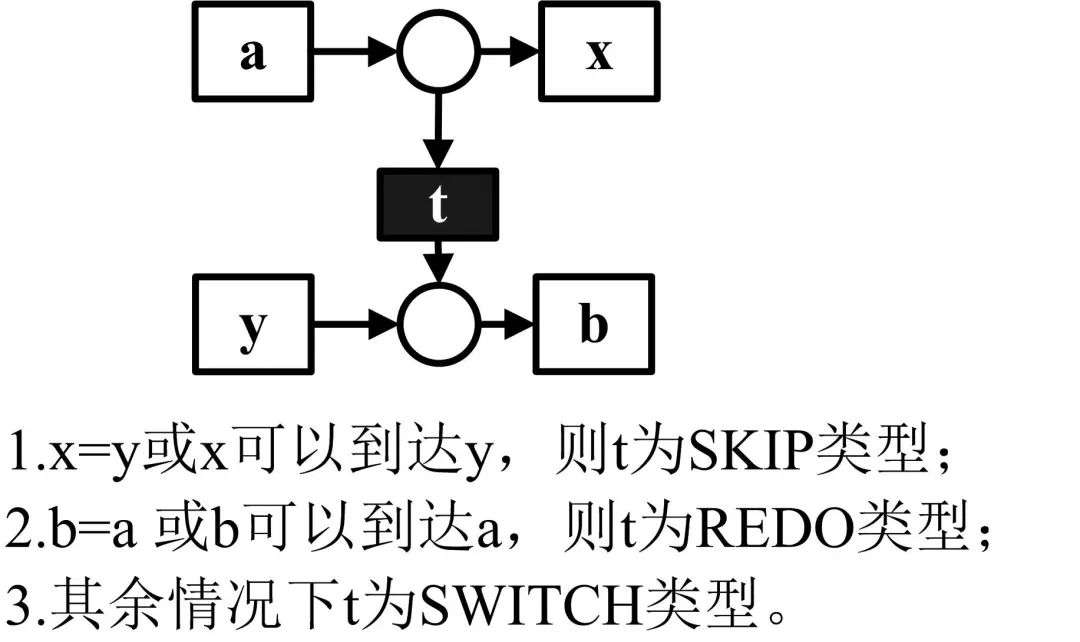
4 Alpha++算法
下图中的N9是非自由选择结构,由于变迁A和D,变迁B和E之间存在远程的依赖关系,导致变迁D和变迁E的执行不再是自由的竞争关系,而基础的Alpha算法不能发现库所p1和p2。
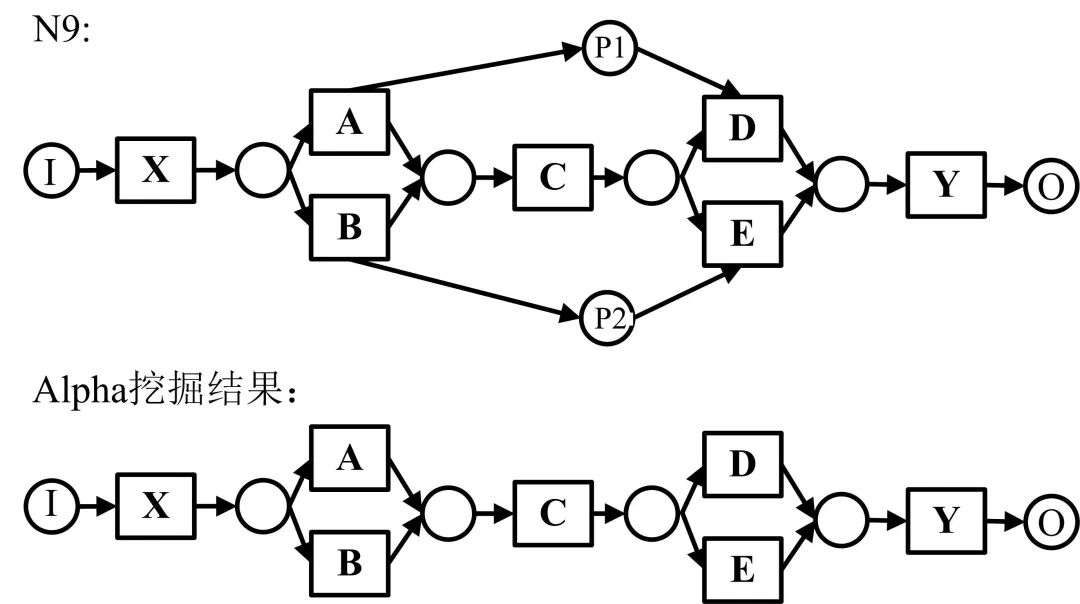
对此,Alpha++算法对此进行改进,引入了任务间非紧邻的可达关系,并推导依赖关系。
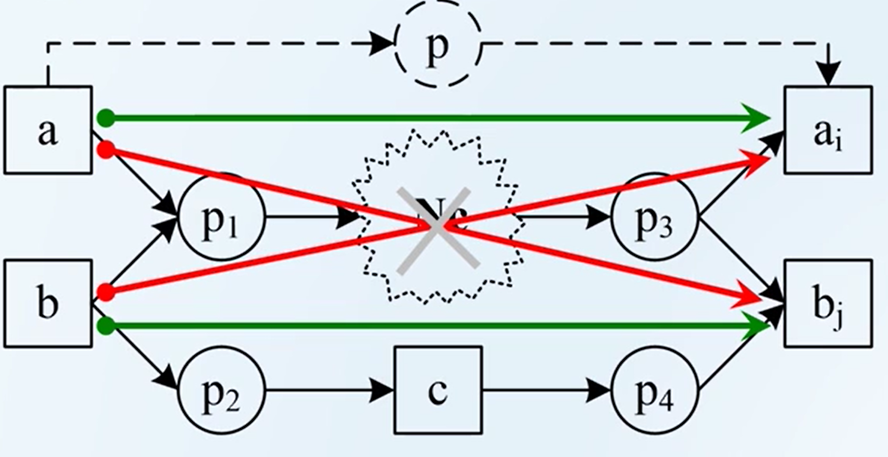
从上图可以发现,变迁a后面永远跟着ai,不会跟着bj,变迁b后面永远跟着bj,不会跟着ai。那么如果ai的输入变迁集合是bj输入变迁集合的子集的话,则相信a和ai之间存在这种没有被发现的库所p。
5 Alpha*算法
我们展示了一个网上购物模型,该模型如下图所示,其中a表示登录,b表示浏览商品对购物篮进行操作,c表示汇总购物篮中的商品计算总钱数,d表示决定购买,e表示交易,f表示退出。
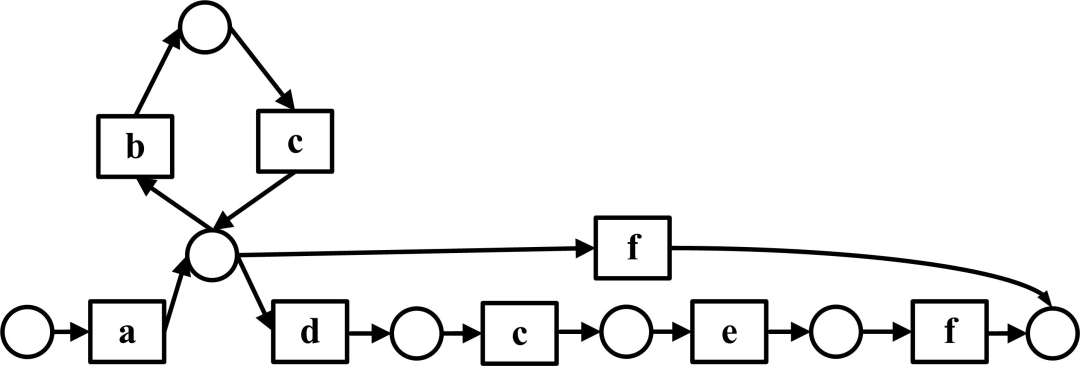
该模型存在重名任务c和f,Alpha算法并不能挖掘该模型,为此Alpha*算法被提出。该算法和Alpha+的思想类似,使用了三阶段的挖掘方法:利用启发式规则重命名日志中的事件,使用其他Alpha算法挖掘后,将任务名字重命名回来。
6 Alpha$算法
Alpha$算法是对Alpha++算法和Aplha#算法的整合。其简单流程思想如下:
1.通过改进的虚假依赖关系检测不可见任务;
2.补充可达的依赖关系;
3.检测非自由选择结构;
4.调整不可见任务。
7 总结
Alpha算法存在的一些问题在Alpha的扩展系列算法中得到了解决,现在我们将其总结如下:
(1) 短循环(Alpha、Tsinghua-Alpha);
(2) 不可见任务(Alpha#、Alpha$);
(3) 非自由选择(Alpha++、Alpha$);
(4) 重名任务(Alpha*)。